Image-to-Image Translation with Conditional Adversarial Networks
Summary
Image-to-Image (or Pix-2-Pix) is a type of conditional GAN that does not use noise to generate its output. Instead, it uses a label map as an input to the generator. The discriminator receives the label map and the generated image to make its decision.
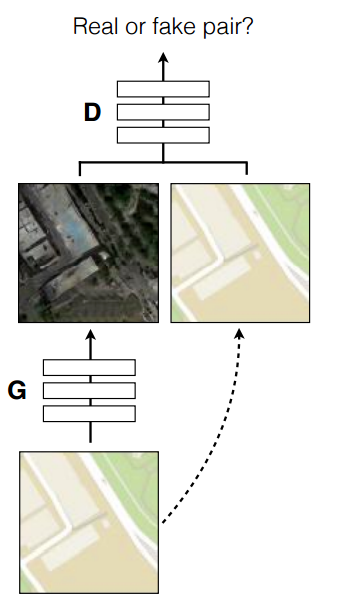
Generator
The generator is basically an U-Net which takes the label map as the input and produces an image.
Discriminator
The discriminator is a normal CNN with a sigmoid activation layer at the end. It also uses LeakyReLU for every convolutional layer. The input of the discriminator is both the label map and the generated image.
Loss
Pix-2-Pix is using the standard conditional GAN loss plus a regularisation term L1.
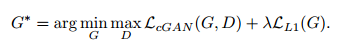
Where lambda is a hyperparameter (100 is suggested).
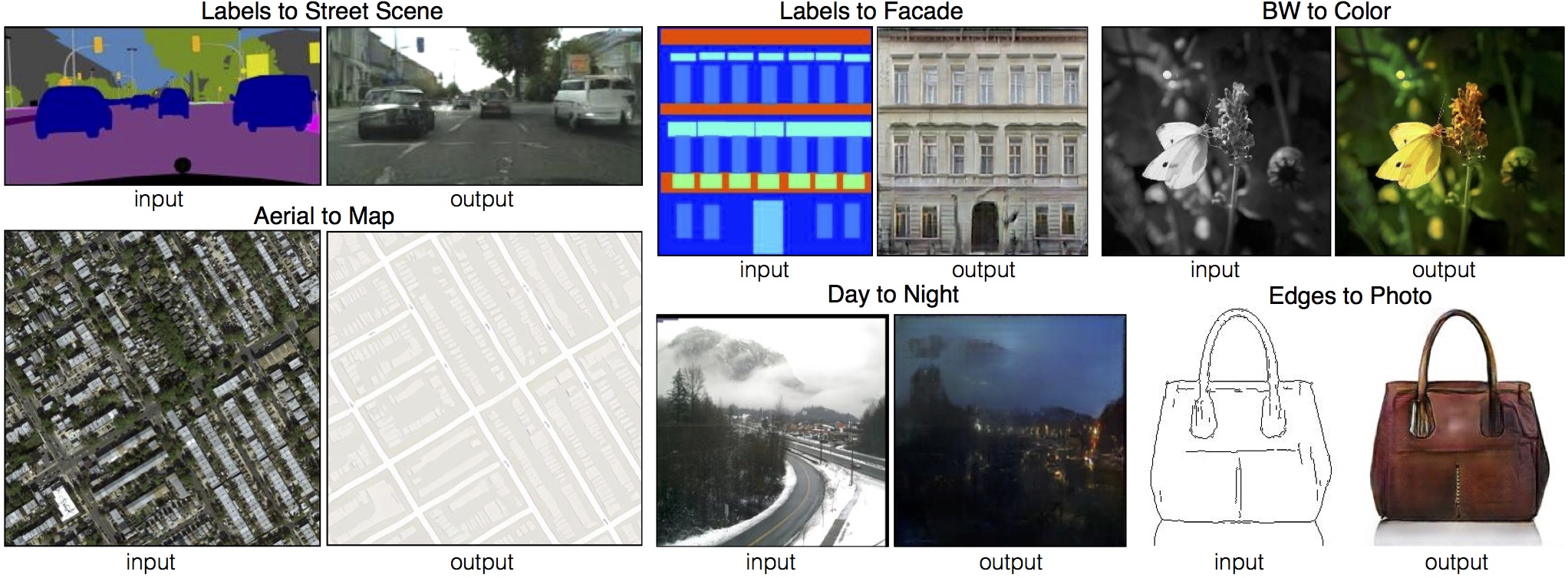
Examples