SSD: Single Shot MultiBox Detector
Summary
SSD is an adaptation of YOLO to support prior boxes. Prior boxes (called default boxes in the paper) are pre-calculated boxes with different aspect ratios and scales. At prediction time, SSD predicts the correct prior box and the associated class. Also, SSD is using multiples feature maps to achieve a better performance.
| Model | Mean avg precision | FPS | Input size |
|---|---|---|---|
| Faster R-CNN | 73.2 | 7 | 1000x600 |
| YOLO (VGG-16) | 66.4 | 21 | 443x443 |
| SSD512 | 76.8 | 22 | 512x512 |
| SSD300 | 74.3 | 59 | 300x300 |
| Fast-YOLO | 52.7 | 155 | 443x443 |
Faster R-CNN works on any input size
Model
The model is using the VGG-16 model for its base. It then uses several feature maps to produce its output.
It’s a more complex model than YOLO but it’s faster because the input size is smaller.
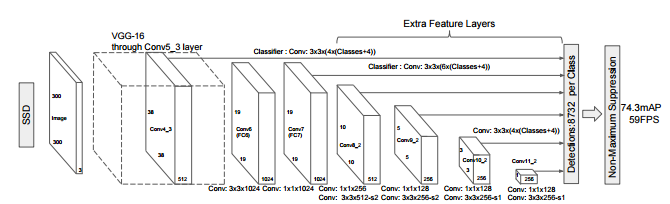
Using Atrous Convolution speeds up the model by 20%
Default boxes
Default boxes are computed from the training sets, they are similar to the anchor boxes from Faster R-CNN. They help the network getting the right aspect-ratio.
Loss
The loss function is similar to YOLO’s loss function. Instead of multiple detections per cell, it predicts a box per prior box. The loss is computed on the prior boxes with a Jaccard overlap bigger than 0.5. This allows multiple predictions per cell.